前言
最近在做一个官网,原本接口做的都是分页的,但是客户提出不要分页,之前看过虚拟列表这个东西,所以进行一下了解。
为啥要用虚拟列表呢!
在日常工作中,所要渲染的也不单单只是一个li那么简单,会有很多嵌套在里面。但数据量过多,同时渲染式,会在 渲染样式 跟 布局计算上花费太多时间,体验感不好,那你说要不要优化嘛,不是你被优化就是你优化它。
进入正题,啥是虚拟列表?
可以这么理解,根据你视图能显示多少就先渲染多少,对看不到的地方采取不渲染或者部分渲染。
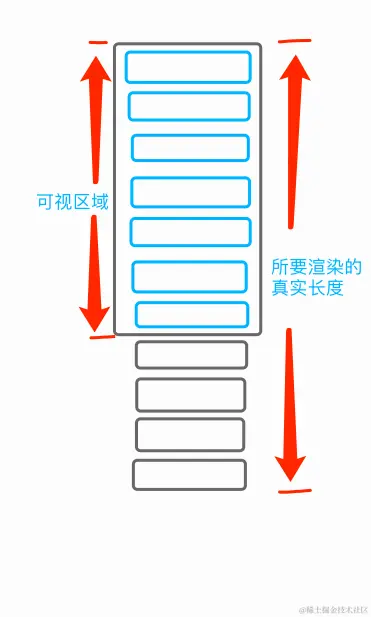
这时候你完成首次加载,那么其他就是在你滑动时渲染,就可以通过计算,得知此时屏幕应该显示的列表项。
怎么弄?
备注:很多方案对于动态不固定高度、网络图片以及用户异常操作等形式处理的也并不好,了解下原理即可。
虚拟列表的实现,实际上就是在首屏加载的时候,只加载可视区域内需要的列表项,当滚动发生时,动态通过计算获得可视区域内的列表项,并将非可视区域内存在的列表项删除。
1、计算当前可视区域起始数据索引(startIndex)
2、计算当前可视区域结束数据索引(endIndex)
3、计算当前可视区域的数据,并渲染到页面中
4、计算startIndex对应的数据在整个列表中的偏移位置startOffset并设置到列表上
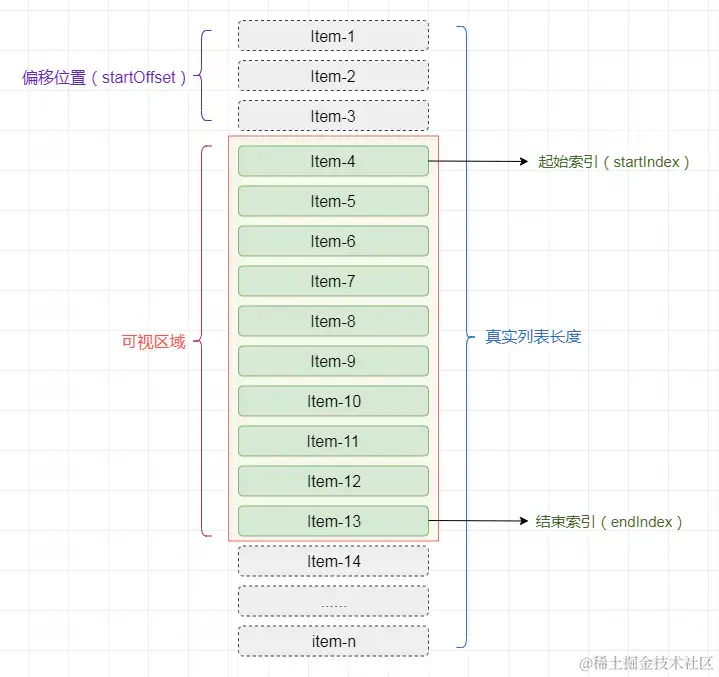
由于只是对可视区域内的列表项进行渲染,所以为了保持列表容器的高度并可正常的触发滚动,将Html结构设计成如下结构:
<div class="infinite-list-container">
<div class="infinite-list-phantom"></div>
<div class="infinite-list">
<!-- item-1 -->
<!-- item-2 -->
<!-- ...... -->
<!-- item-n -->
</div>
</div>
infinite-list-container 为可视区域的容器
infinite-list-phantom 为容器内的占位,高度为总列表高度,用于形成滚动条
infinite-list 为列表项的渲染区域
接着,监听infinite-list-container的scroll事件,获取滚动位置scrollTop
假定可视区域高度固定,称之为screenHeight
假定列表每项高度固定,称之为itemSize
假定列表数据称之为listData
假定当前滚动位置称之为scrollTop
则可推算出:
列表总高度listHeight = listData.length * itemSize
可显示的列表项数visibleCount = Math.ceil(screenHeight / itemSize)
数据的起始索引startIndex = Math.floor(scrollTop / itemSize)
数据的结束索引endIndex = startIndex + visibleCount
列表显示数据为visibleData = listData.slice(startIndex,endIndex)
当滚动后,由于渲染区域相对于可视区域已经发生了偏移,此时我需要获取一个偏移量startOffset,通过样式控制将渲染区域偏移至可视区域中。
时间分片
那么虚拟列表是一方面可以优化的方式,另一个就是时间分片。
先看看我们平时的情况
1.直接开整,直接渲染。
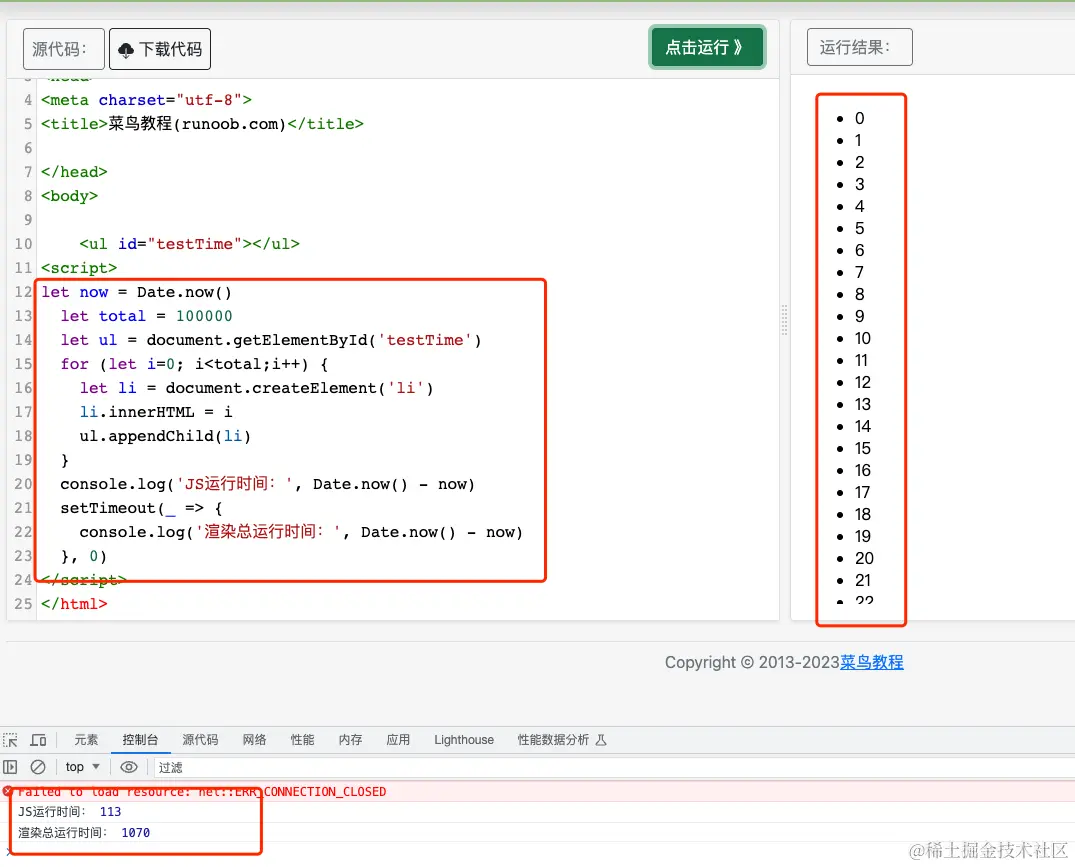
诶???我们可以发现,js运行时间为113ms,但最终 完成时间是 1070ms,一共是 js 运行时间加上渲染总时间。
PS:
在 JS 的 EventLoop中,当JS引擎所管理的执行栈中的事件以及所有微任务事件全部执行完后,才会触发渲染线程对页面进行渲染
第一个 console.log的触发时间是在页面进行渲染之前,此时得到的间隔时间为JS运行所需要的时间
第二个 console.log是放到 setTimeout 中的,它的触发时间是在渲染完成,在下一次 EventLoop中执行的
那我们改用定时器
上面看是因为我们同时渲染,那我们可以分批看看。
let once = 20
let ul = document.getElementById('testTime')
function loopRender (curTotal, curIndex) {
if (curTotal <= 0) return
let pageCount = Math.min(curTotal, once) // 每页最多20条
setTimeout(_ => {
for (let i=0; i<pageCount;i++) {
let li = document.createElement('li')
li.innerHTML = curIndex + i
ul.appendChild(li)
}
loopRender(curTotal - pageCount, curIndex + pageCount)
}, 0)
}
loopRender(100000, 0)
这时候可以感觉出来渲染很快,但是如果渲染复杂点的dom会闪屏,为什么会闪屏这就需要清楚电脑刷新的概念了,这里就不详细写了,有兴趣的小朋友可以自己去了解一下。
可以改用 requestAnimationFrame 去分批渲染,因为这个关于电脑自身刷新效率的,不管你代码的事,可以解决丢帧问题。
let once = 20
let ul = document.getElementById('container')
// 循环加载渲染数据
function loopRender (curTotal, curIndex) {
if (curTotal <= 0) return
let pageCount = Math.min(curTotal, once) // 每页最多20条
window.requestAnimationFrame(_ => {
for (let i=0; i<pageCount;i++) {
let li = document.createElement('li')
li.innerHTML = curIndex + i
ul.appendChild(li)
}
loopRender(curTotal - pageCount, curIndex + pageCount)
})
}
loopRender(100000, 0)
还可以改用 DocumentFragment
什么是 DocumentFragment
DocumentFragment,文档片段接口,表示一个没有父级文件的最小文档对象。它被作为一个轻量版的 Document使用,用于存储已排好版的或尚未打理好格式的XML片段。最大的区别是因为 DocumentFragment不是真实DOM树的一部分,它的变化不会触发DOM树的(重新渲染) ,且不会导致性能等问题。
可以使用 document.createDocumentFragment方法或者构造函数来创建一个空的 DocumentFragment
ocumentFragments是DOM节点,但并不是DOM树的一部分,可以认为是存在内存中的,所以将子元素插入到文档片段时不会引起页面回流。
当 append元素到 document中时,被 append进去的元素的样式表的计算是同步发生的,此时调用 getComputedStyle 可以得到样式的计算值。而 append元素到 documentFragment 中时,是不会计算元素的样式表,所以 documentFragment 性能更优。当然现在浏览器的优化已经做的很好了, 当 append元素到 document中后,没有访问 getComputedStyle 之类的方法时,现代浏览器也可以把样式表的计算推迟到脚本执行之后。
let once = 20
let ul = document.getElementById('container')
// 循环加载渲染数据
function loopRender (curTotal, curIndex) {
if (curTotal <= 0) return
let pageCount = Math.min(curTotal, once) // 每页最多20条
window.requestAnimationFrame(_ => {
let fragment = document.createDocumentFragment()
for (let i=0; i<pageCount;i++) {
let li = document.createElement('li')
li.innerHTML = curIndex + i
fragment.appendChild(li)
}
ul.appendChild(fragment)
loopRender(curTotal - pageCount, curIndex + pageCount)
})
}
loopRender(100000, 0)
其实同时渲染十万条数据这个情况还是比较少见的,就当做个了解吧。






 400 186 1886
400 186 1886


