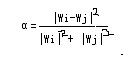[点晴CRM客户管理系统]搜索引擎是如何判断有价值的文章
当前位置:点晴教程→点晴CRM客户管理信息系统
→『 经验分享&问题答疑 』
有很多人咨询过笔者(Mr.Zhao),百度如何判断伪原创和原创?百度喜欢什么样的文章?什么样的文章比较例如获得长尾词排名?等等诸如此类的问题。面对这些问题,我常常不知如何回答。如果我给一个比较大方向一些的答案,例如要重视用户体验、要有意义等等,那么提问者会觉得我在应付他,他们往往抱怨说这些太模糊。可是我也没法再给出具体的内容,毕竟我不是百度,具体算法我又何德何能的为你们指点江山呢? 为此,我开始写这个“如果是我”系列的文章。在这一系列文章里,我假设如果是我绞尽脑汁的来为网民提供较好的搜索服务,我会怎么做,我会怎么对待文章内容、如何对待外链、如何对待网站结构等等诸如此类的站点元素。当然,本人技术有限,我只能写一点我稍微理解的东西。而百度以及其它的商业搜索引擎,他们有大量比我优秀的人才,相信他们的算法以及处理问题的方式会比我完善很多,而我之所以写这些,无外乎抛砖引玉,希望大家看后,心里有一个大概。毕竟在SEO的道路上走过一段时间后,没有谁能够当谁的老师,一些观点仅供参考。 ************重要的声明******************************* 在此,我要郑重声明,这个系列文章中所有涉及到的思想、算法与程序,均非本人所写,全部是我从一些公开的资料里搜集而得的。同时,相信大家也能理解,如果这些免费公开的东西都能做到如此程度,那么那些商业机密就更不用提了。 ****************************************************** 好的,现在开始。 如果是我,我会喜欢什么样子的文章呢?我会喜欢我的用户喜欢的文章,如果硬要加判定标准,那无外乎是两种:1.原创且用户喜欢。2.非原创且用户喜欢。在这里,我的态度很明显,伪原创就是非原创。那么用户喜欢什么样的文章呢?很显然,一些新观点、新知识往往是用户喜欢的,也就是说通常原创文章都是用户喜欢的,而且即便用户不喜欢,原创站点作为新鲜内容的制造者,也应该受到一定的保护。那么非原创的文章用户就一定不喜欢吗?诚然否也。一些站点,其内容往往是经过搜集整理后聚合而成的,那么这些站点对用户来说就是有价值的,其相对应的文章理应获得较好的排名。 由此可见,我需要重视两类文章即可。一是原创文章,二是有价值的信息聚合站点下的文章。 首先要明确一点,本文探讨范围仅限内容页,而非专题页、列表页和首页。 那么我在甄别这两类文章之前,我需要先进行信息的采集。本文对于spider程序部分不进行阐述。当spider程序下载下来网页信息后,在内容处理的模块中,我需要先对内容除噪。 内容除噪,并非大家经常性的误以为仅仅除去代码而已。对于我来说,我还要出去页面部分非正文内容的文字。比如导航条、比如底部文字以及各个文章列表。将它们的影响除去后,我将得到一段仅仅包含网页正文内容的文本段落。写过采集规则站长朋友应该知道,这个并不难。但搜索引擎毕竟是一款程序,不可能针对每个站写个类似于的采集规则的东西,所以我需要建立一套除噪算法。 在此之前,我们先明确我们的目的。
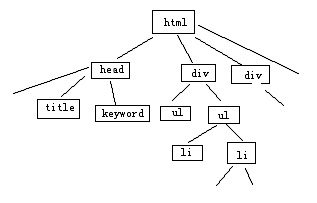
上图中很明显内容1是用户最为需要的,内容2是用户可能感兴趣的,其余均是无效的噪音。那么针对于此,我们可以发现如下几特征: 1.所有的调用列表全部是在一个信息块里,这个信息块绝大部分是由标签组成,即便有游离于标签的内容,其文字也基本是固定的,且在站内页面中存在大量重复,较为容易判断。 2.内容2一般紧邻着内容1。而且内容2中的链接锚文本,与内容1存在相关性。 3.内容1部分,是有文字文本内容和标签混合而成,且在通常情况下,文本文字内容在网站网页集合中具有唯一性。 那么,针对于此,我采用广为人知的标签树方式,将内容页进行分解。 从网页的标签布局上来看,网页是通过若干的信息块来提供内容的,而这些信息块又是由特定的标签规划出来的,常见的标签有<div><ul><li><p><table><tr><td>等,我们依照这些标签,将网页费解为树状结构。
上图是我手绘的简单的标签树,通过这种方式,我可以非常轻松的识别出各个信息块。然后我设定一定阙值A为内容比重阙值。内容比重阙值为信息块中文本字数与标签出现此处的比值。我设定当网页中信息块内容比重阙值大于A时,才会被我列为有效内容块(此举是为了杜绝过分的多内链,因为如果一篇文章布满内链,则不利于用户体验),然后我再比对内容块中的文本,当其具有唯一性时,此一个或多个内容块的集合,即为我所需要的“内容1”。 那么内容2我要如何处理呢?在讲解处理内容2之前,我先讲解一下内容2的意义。正如我先前所说,如果是一个注重用户体验的聚合性网站,那么他的作用是将现有的互联网内容经过精心的分类与关联,来方便用户更好、更有效的阅读。针对这样的站点,即便其文章不是原创而是从互联网上摘抄的,我也会给予其足够的重视与排名,因为它良好的聚合内容往往更能满足用户的需求。 那么针对聚合站点,我可以通过“内容2”来进行粗略的判断。简而言之,如果是一个良好的聚合站点,首先其内容页必须存在内容2,同时内容2必须占重要部分。 好了,识别内容2很简单,对于内容比重阙值低于某个特定值的信息块,我全部判断为链接模块。我将内容1通过某些方式(具体方式本文后半部分讲解),提取出主题B。我将链接模块中的所有标签的锚文本分别进行分词,如果所有的锚文本均与主题B相符,则将此链接模块判定为内容2。设定链接阙值C,链接阙值为内容2中标签出现次数除以所有链接模块所出现的标签次数所得的比重,若大于C,则此网站可能为聚合网站,针对内容排名计算时会引用聚合站点特定的算法。 ******************拓展阅读1开始*************************************** 我相信很多SEO从业者刚接触这行时,就听说过一件事,就是内容页面导出链接要具有相关性。还有一件事,就是页面下面要有相关阅读,来吸引用户纵深点击。同时应该还听人讲过,内链要适中,不可太多等。 但很少有人会说为什么,而越来越多的人因为不明其内在道理,而渐渐忽视了这些细节。当然,以前的一些搜索引擎算法在内容上的注重程度不够,也起到了推波助澜的作用。但是,如果从阴谋论的角度上来看,我可以假设出这么一个道理。 绝大部分用户的搜索页面,第一页只有10个结果,除去我自家产品,往往仅剩下7个左右,一般用户最多只会点击到第3页,那么我需要的优质站点其实不到30个就可以最大限度的满足用户体验。那么经过3-5年的布局,逐渐筛选出一些耐得住寂寞和认真做细节的站,这时候我再将这一部分算法进行调整,进而筛选出这些优质站点,推送给用户。当然,在做的过程中还有更多的参考因素,比如域名年龄、JS数量,网站速度等。 ******************拓展阅读1结束*************************************** ******************拓展阅读2开始*************************************** 你们说,为什么当站文章中有大量相同时,会快速引起搜索引擎惩罚呢?这里我说的不是摘抄与原创的问题,而是你站内自己和自己的文章重复。之所以搜索引擎反应这么快,同时惩罚严厉,根本原因就是在你的文章中,他提取不到内容1。 ******************拓展阅读2结束*************************************** 好,经过这一系列处理,我已经获得了内容1与内容2了,下面该进行原创识别的算法了。 现在基本上搜索引擎对于原创的识别,在大面上采用的是关键词匹配结合向量空间模型来进行判断。Google就是这么做的,在其官方博客有相应的文章介绍。这里,我就做个大白话版本的介绍,争取做到简单易懂。 那么,我通过分析内容1,得到内容1中权重最高的关键词k,那么按照权重大小进行排序,前N个权重最高的关键词的集合我命名为K,则K={k1,k2,……,kn},则每一个关键词都会对应一个其在页面中获取到的权重特征值,我将k1对应的权重特征值设定为t1,则前N个权重关键词对应的特征值集合则为T={t1,t2,……,tn},那么我们有了这个特征项,就能计算出其相对应的特征向量W={w1,w2,……,wn}。接着我将K拼成字符串Z,同时MD5(Z)则表示字符串Z的MD5散列值。 那么假定我判定的两个页面分别是i与j。 则我计算出两个公式。 1.当MD5(Zi)=MD5(Zj)时,页面i与页面j完全相同,判断为转载。 2.设定一个特定值α
当0≤α≤1的时候,我判定页面相似为重复。 由此,对于原创文章的判断就结束了。好了,苦逼烦闷的枯燥讲解告一段落,下面我用大白话再重新复述一遍。 首先,你的内容一模一样,一个字都不带改的,那肯定是摘抄的啊,这时候MD5散列值就能迅速的判断出来。 其次,很多SEO他们懒,进行所谓的伪原创,你说你伪原创时插入点自己的观点与资料也成,结果你们就是改个近义词什么的,于是我就用到了特征向量,通过特征向量的判断,把你们这些低劣的伪原创抓出来。关于这个,判断思想很简单,你权重最高的前N个关键词集合极为相似的时候,判断为重复。这里所谓的相似包括但不仅仅局限于权重最高的前N个关键词重合,于是构建了特征向量,当对比的两个向量夹角与长度,当夹角与长度的差异度小于某个特定值的时候,我将其定义为相似文章。 ********************备注1开始************* 一直关注google反作弊小组官方博客的朋友们,应该看过google关于相似文章判断算法的那篇博文,在那篇文章中,其主要使用的是余弦定理,就是主要计算夹角。不过后来Mr.Zhao又看了好几篇文献,觉得那篇博文应该仅仅是被google抛弃后才解密的,现在大体算法的趋势,应该是计算夹角与长度,所以选择现在给大家看的这个算法。 ********************备注1结束************* 好的,这里我们注意到了几个问题。 1.α被判定为重复时的取值范围是否可变? 2.内容中如何提取出关键词? 3.内容中关键词的权重值是如何赋予的? 下面我来逐一解答。 先说α判断重复时的取值范围,这个范围是绝对可变的。随着SEO行业的蓬勃发展,越来越多人想要投机取巧,而这是搜索引擎不能接受的。于是就会隔几年进行一次算法大更新,而且每一次算法大更新,都会预告会影响百分之多少的搜索结果。那这影响结果的百分数是如何计算出来的?当然不是一个一个数的,在内容方面(其它方面我会在其它文章中阐述),是通过调整α判断相似度时的取值空间变化来计算的,每一个页面在被我处理是,我所计算出的α值都会存储在数据库中,这样我在每次算法调整时,风险都可做到最大的控制。 那么如何提取关键词?这就是分词技术了,我待会再讲。页面内不同关键词的权重赋值也在待会讲。 关于文章相似性,简而言之,就是以前大家改一改文章,比如“越来越多SEO开始重视起文章的质量。”改为“高质量的文章被更多的SEO所重视”,这个在以前没有被识别出来,不是我没有识别你的技术,而是我放宽范围,我可以随时在需要的时候,通过设定参数的取值范围,来重新判断页面价值。 好,如果这里你有些糊涂,别着急,我接着慢慢的说。上述算法里,我需要知道前N个重要的关键词以及其所对应的权重特征值。那这些数值我如何获取呢? 首先,要先分词。针对于分词,我先设定一个流程,然后采用正向最大匹配、逆向最大匹配、最少切分等方式中的一种来进行分词。这个在我会在我的博文《常见的中文分词技术介绍》中讲解,在此不再赘述。通过分词,我得到了这个页面内容1的关键词集合K。 在识别内容1的时候,我就已经构建了标签树,那么我的内容1实际上已经被标签树拆解为由段落组成的树状结构了。
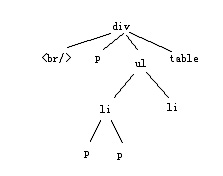
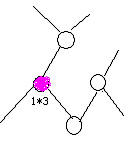
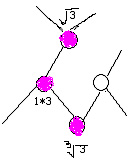
上图是内容1的标签树。在这里,我遇到一个问题,那就是针对标签树权重赋值的时候,应该是面向整个页面的标签树,还是仅仅面向内容1的标签树的? 很多朋友可能会认为,既然是针对内容1的关键词进行赋值判断,那只处理内容1就好了。其实不然。一款搜索引擎,其处理的数据少说也要千万级别的,所以搜索引擎对于高效率的代码与算法要求是极高的。 而正常情况下,一个网站的网页是不可能孤立存在的,在对一个页面针对某一个关键词进行排序的时候,除了要考虑站外因素外,我需要考虑站内权重的继承,那么在考虑站内权重继承的时候,我必然避不开内链的计算,同时内链本身也应该有不同的权重区分,而内链权重计算时,我肯定要考虑其所在页面与其相关性。既然如此,我就应该一次性对整个页面所有的信息块进行权重分配,这样才是高效率,同时也充分体现了内容与链接相关性的重要性。用一句大家常能在网上看见的话来说,就是相关性决定了链接投票的有效性。 好,既然确定下是整个标签树进行权重赋值,那么下面开始。 首先,我要确定重要关键词的词库。重要关键词的确定通过两种方法: 1.不同行业的重点关键词。 2.针对句子结构与词性的重点关键词。 每一款较为成熟的商业搜索引擎,针对不同行业,其算法都会有所不同。而行业的判断,就是依托于各个行业的关键词库进行的。最近百度针对一些特定关键词,在搜索结果中返回网站的备案信息和认证信息,由此可见,词库其实早已存在。 那么,句子结构又从何说起呢?中文句子不外乎主谓宾定状补几个结构组成,而词性也仅有名词、动词、介词、形容词、副词、拟声词、代词、数词。相信很多人刚做SEO的时候,肯定听说过搜索引擎除噪的时候,会去掉的地得和代词,其实这种说法大面上对,但也并非完全准确。从根本原理来说,是针对句子结构与词性而给予处理时的态度不同。我们可以肯定,主语一定是最重要的部分,往往一句话主语变了,其针对的事物和所要表述的意义也就往往不同。而针对的事物若有变化,极有可能导致这篇文章所涉及的行业有所变化。故而,主语肯定是我所需要的重点词。这里为什么我没有说在主语部分去掉代词呢?因为往往去掉主语会使得句子失真,所以我要保留主语所有属性的词,即便是看起来没有意义代词。 那么定语呢?往往定语决定了一个事物的程度或性质,所以定语也很重要。但问题就来了,对于用户来说,美丽的画与漂亮的画是同一个意思,而美丽的画与难看的画却是相反的意思。同时其它句子结构例如补语作为句子的补充,往往承载了地点、时间等信息量,那也很重要。若是如此,那我又要如确定我认为最主要的关键词呢? 这个问题确实很复杂,但其实能够解决它的办法既简单又困难。那就是时间与数据的积累。也许有人会觉得我这么说是不负责任,但事实却是如此。倘若这个世界上没有SEO、没有伪原创,那么搜索引擎可以高枕无忧,因为没有伪原创的干扰,搜索引擎可以迅速的识别出转载内容,然后非常轻松的计算排名。但有了伪原创之后,其实每一次内容判断算法的调整,更多的是对目前一些常见的伪原创做法进行识别。正因为有伪原创的存在,如果是我设计策略,我会设计出两个词库,词库A是用于区分内容所从属的行业,词库B则是针对不同行业,然后在设置若干规则与这两个子词库进行关联。 举例。比如伪原创猖獗的医疗SEO,通过一些病种词,可以迅速识别出其内容属于医疗行业。那么在选择的时候,鉴于某些原因,我将严厉对待医疗,则我认为医疗文章内容重要的仅仅是充当主语的名词,然后在充当主语的名词中,病种名词作为最优先,进而进行优先级排序,在排序中若主语名词数大于N,则按照其所处的信息块距离根节点最近最有先原则,并且同一名词仅选择一次,然后选取前N个重要关键词作为赋值的初始节点,进行权重赋值。 那么在赋值的时候,我设定赋值系数e,我可以判断在这几个被赋值的节点上,根据关键词种类来确定赋值的比重。比如与title中重复的病种名词,其对应的系数为e1,与title中不对应的病种名词系数为e2,其它名词系数为e3。然后我开始遍历标签树。 整个页面自身权重为Q,按照前N个关键词的顺序依次遍历。那么我的遍历原则如下: 1.第一次遍历时,第一个重要节点权重值为Qe1,其父节点权重值为Qe1*b,其子节点权重值为Qe1*c,然后以此原则继续遍历父节点的父节点及其父节点的子节点和子节点的子节点及其子节点的父节点。 以下举例。假定Q为1,e1为3 则一开始如下图
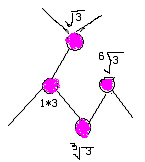
然后假定a为上一个数的平方根,b为上一个数的立方根。则如下图
接着开始遍历其它节点。
当整个网页标签树的所有节点全部被赋值后,第一次遍历结束。这时候开始第二次遍历,注意这时候与e2相乘的就不是Q了,而是第二个重要关键词所在节点的当前权重值。 这样经过N此遍历,每一个信息块都会有自己相对应的权重数值,然后我单独提取内容1的信息块,具体上文中有画图,在此就不再多画了。将内容1量化。量化后,我就能够得到上文中我所需要的权重特征值T={t1,t2,……,tn}。由此,这个算法层就首位相应的完善了。量化公式很多,我在此就不举例了,因为这个举例毫无意义,我又不是真写搜索引擎。 *******拓展阅读3开始************************************ 链接模块的权重,将最后被超链接传到至其所指向的页面中。这也说明了不同位置的链接,其传导的权重各不相同。内链的位置决定了内链的权重继承。而大家经常听到的,内链上下文要出现关键字,其实就是这个算法所衍生出的现象。 *******拓展阅读3结束************************************ 至此,这个算法层基本结束了。 ******声明1开始***************************************** 1.我再次强调,文中算法不是我写的,是我借鉴别人的,借鉴谁的?我忘了……,好多好多。 2.所有有经验的商业搜索引擎,其算法肯定是分层的,绝对不会仅仅是一个算法层,所以这个单一的算法层,对排名来说可以说影响很大,但绝对不是完全按照这一个算法层来进行排名的。 3.本文首发Mr.Zhao的SEO博客,转载请保留原文出处:http://www.seozhao.com/379.html ******声明1结束***************************************** 那么大致了解了这一个层的算法之后,对我们的实际操作有什么具体的帮助吗? 1.我们可以有效知道,如何合理的设置内容页的栏目布局,使得我们在转载文章时,让百度知道我们在转载文章的同时,为了更好的用户体验而聚合了各方观点的文章。 2.我们可以更好的知道,哪些文章会被判定为相似文章。 3.这个是最重要的一点,就是我们能够更好的对内容页面进行布局。真正的白帽SEO,在对站内进行梳理时,其站内栏目在页面上的布局尤为重要,有经验的SEO能够有效的利用页面的权重继承,进而增加长尾排名,这对于门户网站或是B2C等拥有大量内容页的网站来说,非常重要。当然,在长尾排名方面,对页面权重传输的了解与布局仅仅是基础,今后我会在后续文章中,在对栏目层级设置与权重传递方面,针对我的观点进行阐述。 4.明白内链权重继承的大致原理。 该文章在 2025/2/24 15:43:48 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886